Grokking: Shortening the Delay
How we reduced a 332,000-step generalization delay down to just 1,050 steps.
AI models sometimes memorize training data perfectly but still can't answer new questions for a very long time. This phenomenon is called grokking. We tested three strategies to shorten this delay, achieving speedups ranging from 8x to 316x.
All experiments use a small model on controlled arithmetic tasks. We cannot guarantee these results transfer to large-scale language models; generalization to other domains is left for future work.
What we did
Trained a small AI model on simple math problems and tested three strategies to help it generalize faster: training on more varied problems, switching training algorithms, and changing how the model starts.
What we didn't do
We did not test large models, real-world tasks, or practical applications. Results are specific to small models on a controlled arithmetic setting used here as a research tool.
Our contributions
We built the full training pipeline from scratch and ran original experiments on task diversity. Other experiments extend prior research (Power et al., 2022; Lyu et al., 2024) with new results.
What is Grokking?
Imagine a student who studies for a test by memorizing every answer in a textbook. At first, they would fail any test that asks new questions, because they memorized answers, not concepts. But after reviewing the material long enough, something clicks: they truly understand the underlying ideas and can answer any version of the test.
Grokking is the AI equivalent of this experience. First described by Power et al. (2022), it refers to a two-phase learning pattern where a model nails the training examples almost immediately, then appears completely stuck before suddenly generalizing perfectly to new examples.
Phase 1: Memorization
The model quickly learns to answer every training question correctly, but only by remembering them like a lookup table. Ask it anything new and it fails. This happens very early in training.
Phase 2: Generalization
Much later, something shifts internally. The model stops relying on memorized answers and starts understanding the underlying pattern. Accuracy on new questions then jumps sharply.
The gap between Phase 1 and Phase 2 can be enormous, sometimes hundreds of thousands of additional training steps.
Training AI is expensive, so shortening this gap has real practical value.
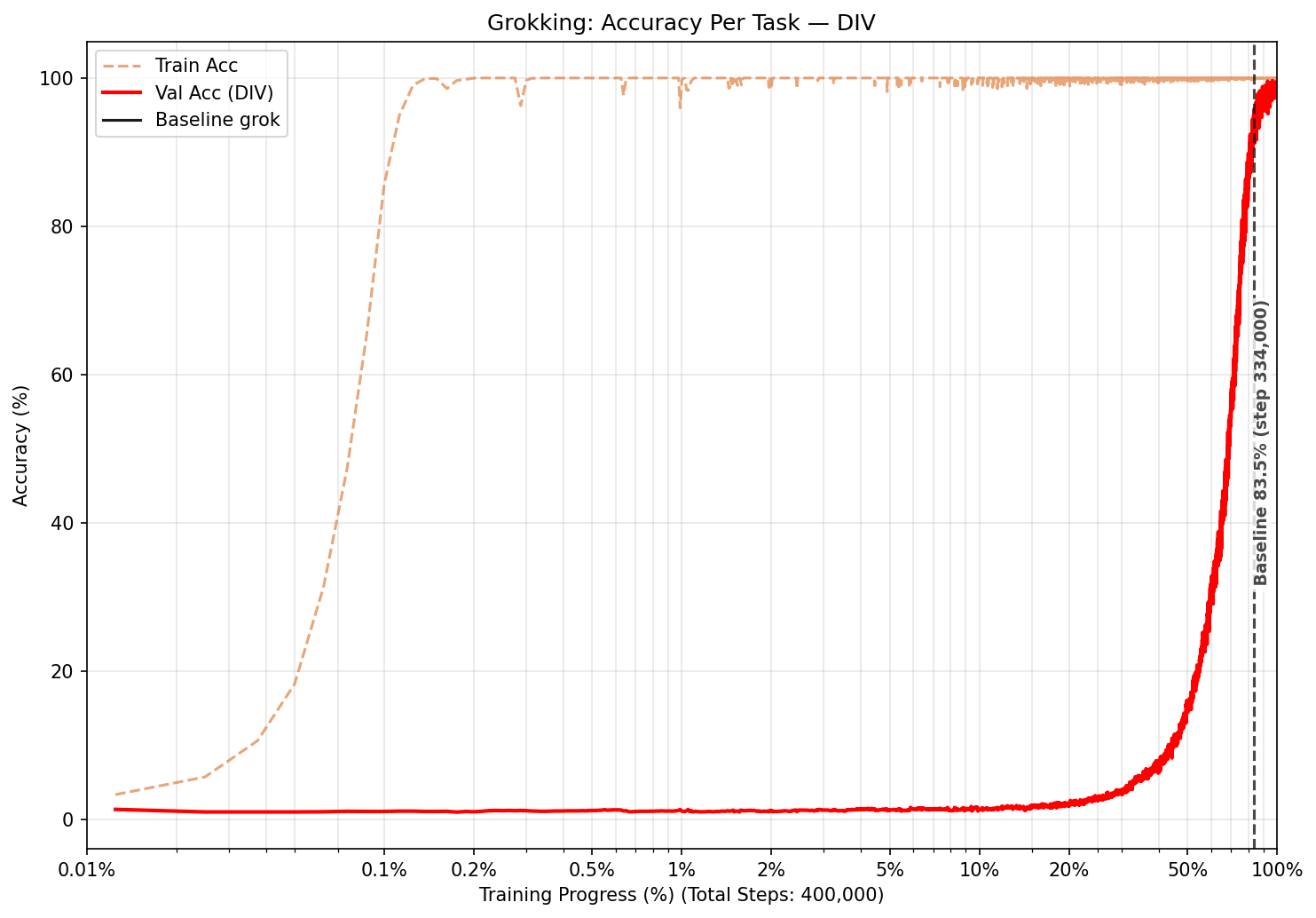
Why Does Grokking Happen?
When an AI model trains, it is constantly trying to reduce its mistakes. Early on, the easiest way to do this is to memorize: remember exactly what answer goes with each training question. This works perfectly for the training set, but teaches the model nothing useful about the underlying pattern.
Over time, a training technique called weight decay, which gently discourages the model from
growing overly complicated, slowly pushes it toward a simpler, more general solution. When the model finally
finds that simpler solution, generalization happens suddenly and dramatically.
In short: the model takes the easy route first (memorization), and only later, under pressure, finds the right
route (understanding). Our goal was to find ways to make that transition happen faster.
Our Approach
We used clock (modular) arithmetic as our testing ground: a type of math where numbers wrap around after reaching a limit, just like a clock that resets after 12. For example, 10 + 5 on a 12-hour clock is 3, not 15. Our version wraps around at 97. The model's job is to predict the correct wrap-around result given two numbers and an operation.
All results are reported as training progress %, how far through training the model was when it generalized, rather than raw step counts. This makes it easy to compare experiments that ran for different lengths. We define "generalized" as when the model first answers at least 95% of new questions correctly, following the standard used in prior work. Small differences below ~1% training progress should be interpreted cautiously.
The Model
A small Transformer (the same family of architecture behind ChatGPT) with around 400,000 internal connections, compared to billions in production systems.
The Training Algorithm
By default we used AdamW, a popular and stable training algorithm. One experiment swapped this for SGD (Stochastic Gradient Descent), a simpler and noisier alternative.
The Tasks
Four arithmetic operations using wrap-around math:
Division (hardest to learn)
Multiplication
Addition
Subtraction
Experiment 1: Task Diversity
Our first strategy: train on multiple types of arithmetic at the same time rather than just one. A model trained on all operations at once cannot rely on memorizing shortcuts for any single task. It has to find the deeper pattern they all share.
Training all four tasks together
We scaled total training time so each task received the same amount of training examples as in a single-task run. Every task generalized dramatically faster:
1st: Multiplication
Generalized at 4.3% training progress (68,250 steps)
2nd: Division
Generalized at 4.7% training progress (75,750 steps)
3rd: Addition
Generalized at 6.5% training progress (104,150 steps)
4th: Subtraction
Generalized at 7.8% training progress (124,650 steps)
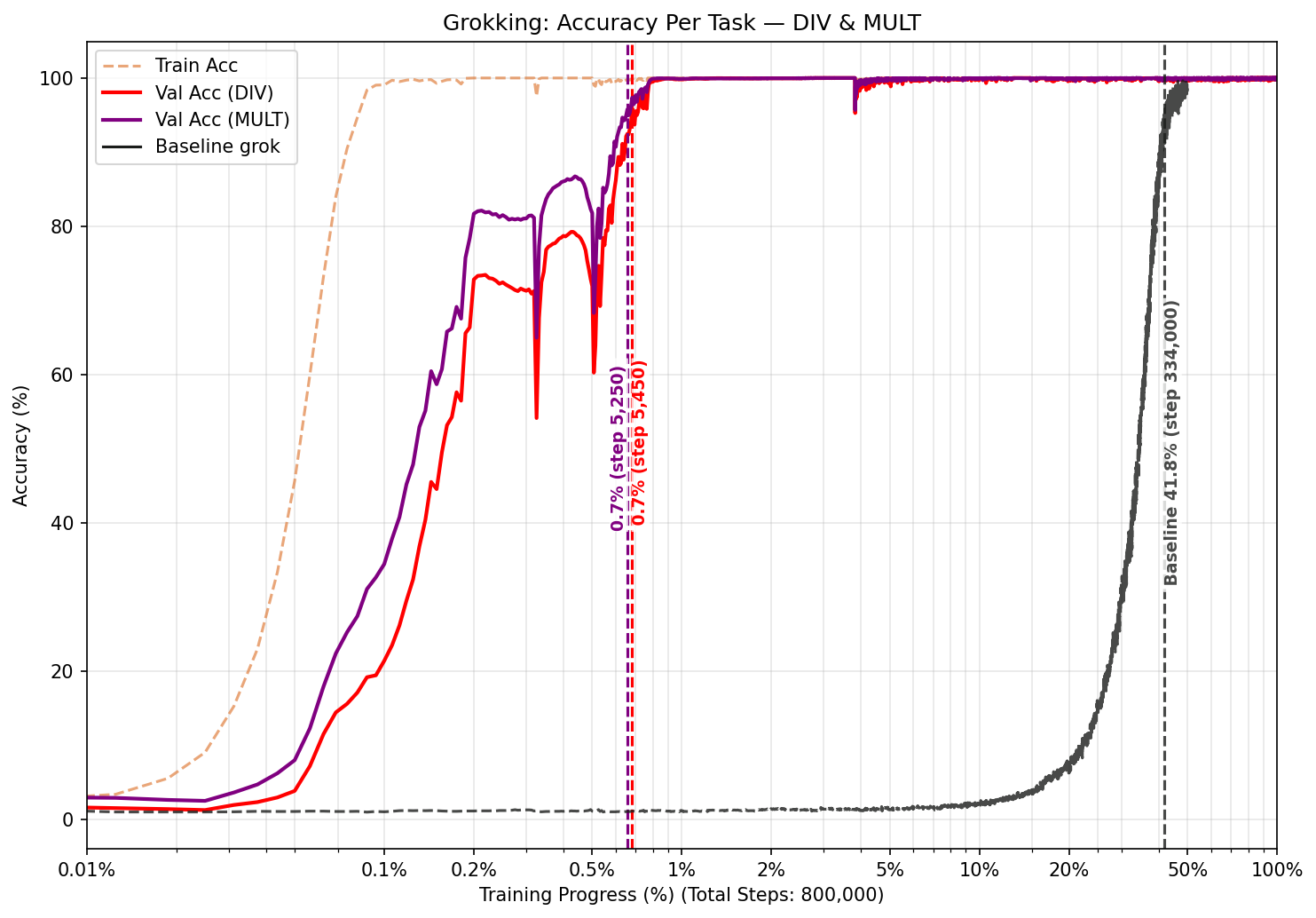
Two-task combinations
Not every pairing helped equally. Pairing division with multiplication was by far the best result: both tasks generalized at just ~0.7% training progress, a ~119x speedup. Pairing division with addition or subtraction actually made things worse than training on division alone.
We think this is because division and multiplication are mathematically similar (both involve a kind of inverse
operation) while addition and subtraction work differently. When two tasks are similar enough, the model finds
shared patterns that help both. When they are too different, they may pull the model in conflicting directions.
What we learned along the way
In early runs, randomly mixing tasks in each training batch caused one task to dominate and hurt the others. We fixed this by scaling total training time with the number of tasks, ensuring each task always received equal representation.
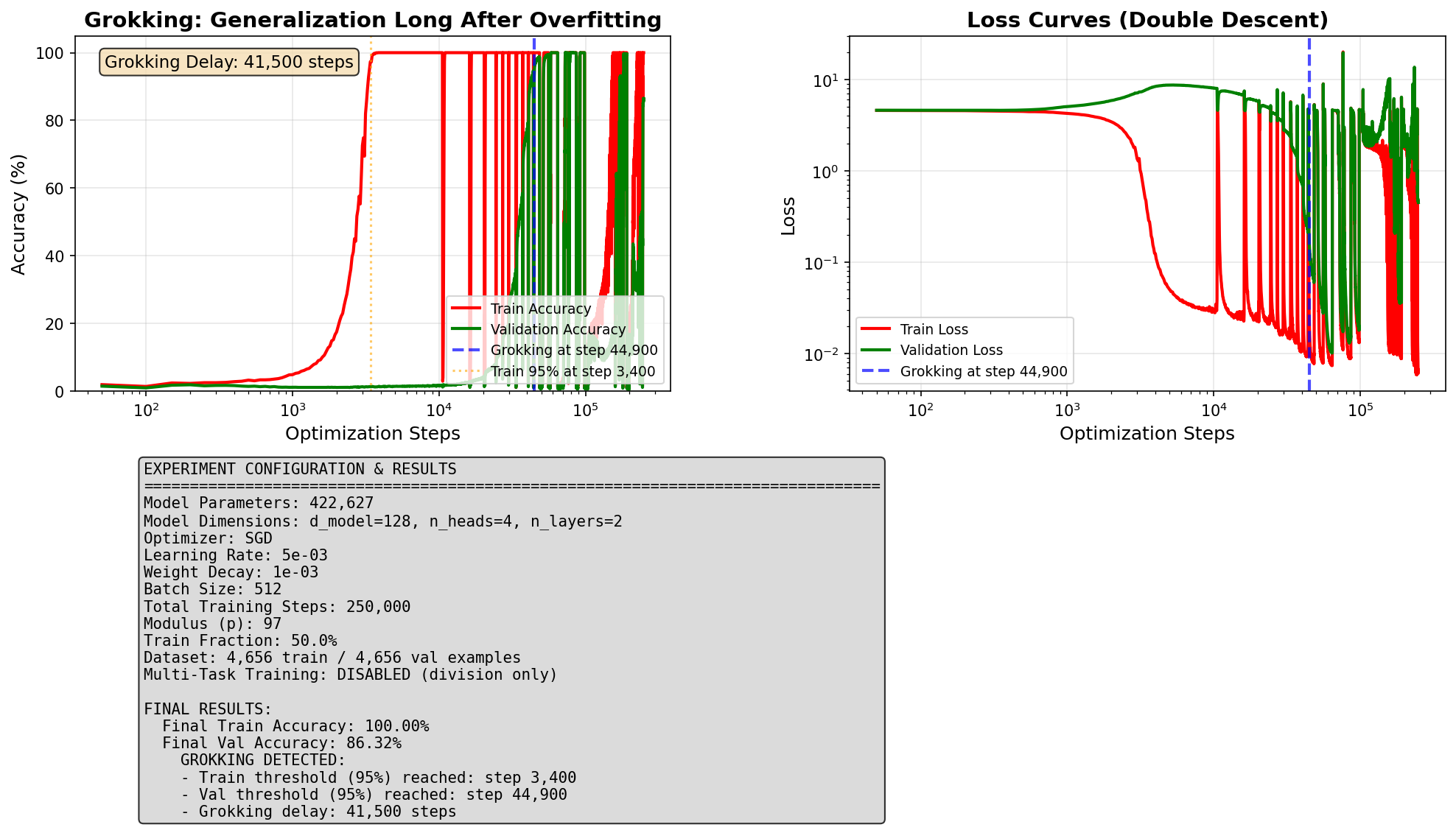
Experiment 2: Introducing Noise
Our second strategy: swap the default training algorithm for a noisier one. AdamW carefully smooths each update to keep training stable. SGD is less careful: its updates are rougher and less predictable. That roughness can help shake the model out of the memorization trap, much like jostling a stuck drawer can suddenly free it.
Too much noise: Unstable
The model generalized very quickly but then immediately fell apart. Too much noise is destabilizing and not usable in practice.
Moderate noise: Stable
Generalized at step 44,900, roughly 8x faster than the baseline. Final accuracy: 86%. A real speedup, but with a tradeoff.
The tradeoff: The stable run was 8x faster, but final accuracy capped at ~86% rather than ~100%.
The same roughness that helped escape memorization also prevented the model from fully converging later on.
Whether this tradeoff is worth it depends on whether speed or accuracy matters more for a given use case.
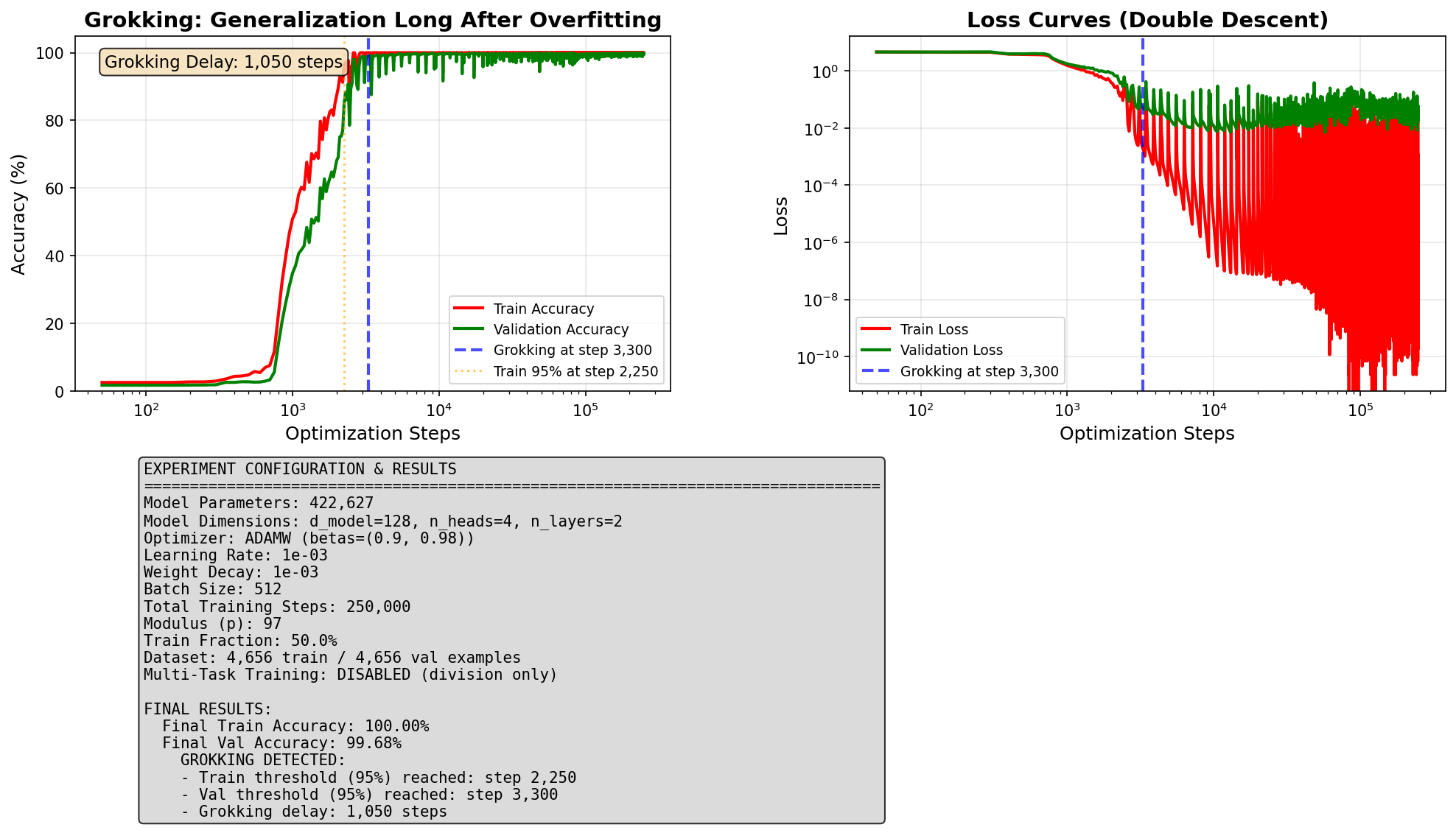
Experiment 3: Starting Small
Our third strategy: limit the model's capacity right from the start. Normally, a model begins training with all its internal connections active, giving it plenty of room to build a memorization circuit. What if we dramatically reduced that starting capacity?
Sparse start (90% inactive)
90% of connections set to zero at the start.
Generalization delay: 1,050 steps
Final accuracy: 99.68%
Tiny-scale start
All connections initialized at a very small value.
Generalization delay: 1,050 steps
Final accuracy: 73.75%
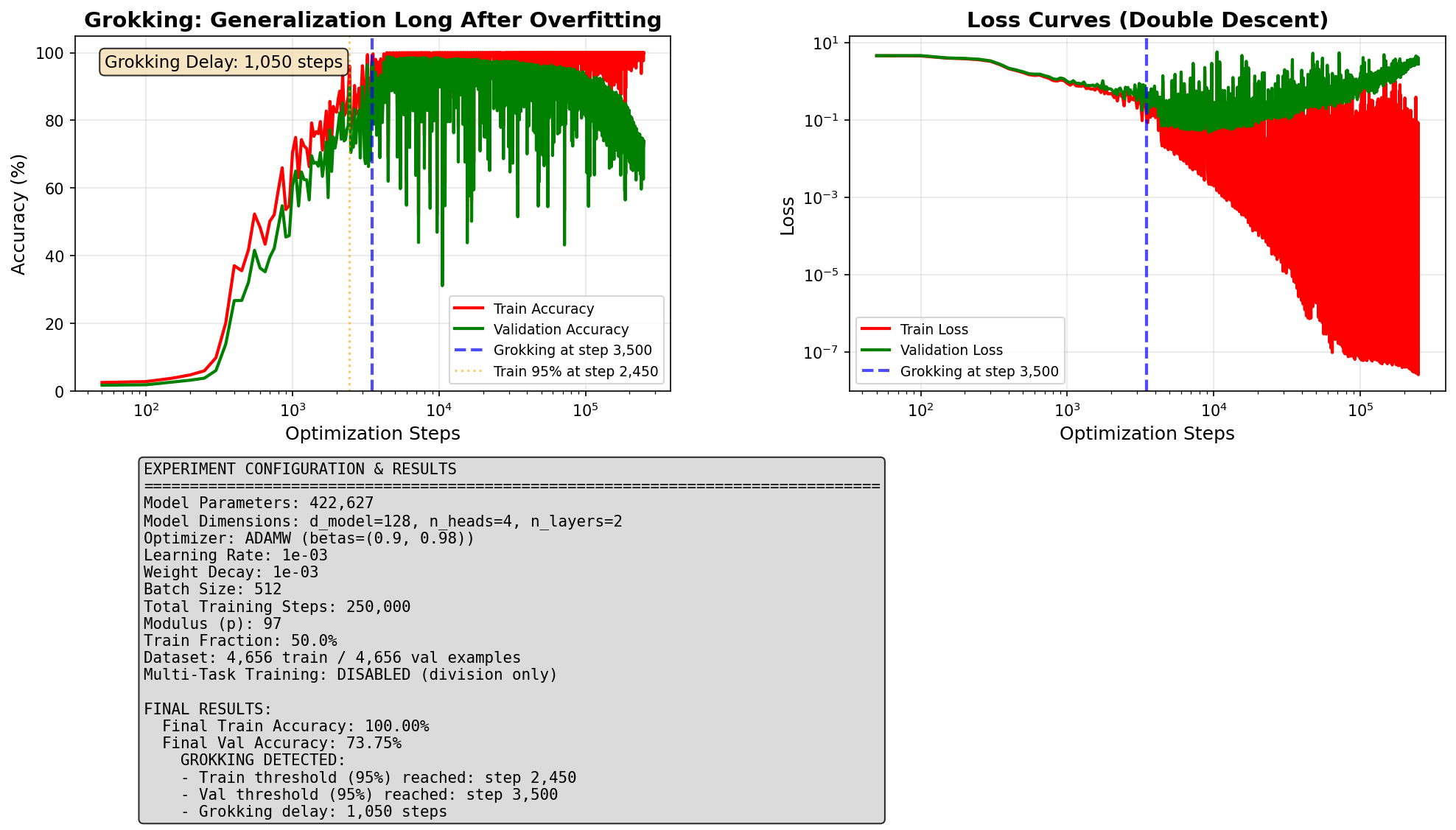
Open Question: It is unclear whether starting sparse would still work for larger, more powerful models. Those models may genuinely need their full capacity to learn at all. Testing this is an important direction for future work.
Summary & Takeaways
Across three experiments, we showed that the delay between memorization and generalization is not a fixed feature of how AI learns. It can be dramatically shortened. All three strategies share a common thread: they work by preventing the model from over-committing to memorization in the first place.
Task Diversity
Train on all four operations at once.
83.5% to 4.7% progress for Division.
~18x speedup. Full accuracy maintained.
Noisier Training
Swap training algorithm to SGD.
332,000 to 41,500 step delay.
~8x speedup. Final accuracy capped at ~86%.
Sparse Start
Begin with 90% of connections inactive.
332,000 to 1,050 step delay.
~316x speedup. Full accuracy maintained.
Why does this matter?
Training AI models is slow and expensive. Anything that helps models generalize faster without sacrificing accuracy has direct practical value. Our results point to two particularly promising levers: training on diverse, related tasks and starting with a constrained model. Both are simple to apply and produce large speedups in our setting. Whether these benefits carry over to larger, real-world models is the key open question.
Limitations
Our experiments used a small, controlled research setting with a fixed model size and a single type of wrap-around arithmetic. We cannot say whether the same strategies would work for large AI models used in real-world products. Our explanation for why task diversity helps is a hypothesis we did not directly verify by examining the model's internals. And our 95% accuracy threshold for defining "generalized" is a convention: small differences in timing between experiments should not be over-interpreted.
References
Power et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. arXiv:2201.02177.
Lyu, Jin, Li, Du, Lee & Hu (2024). Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking. ICLR 2024.
Kim et al. (2025). Task Diversity Shortens the ICL Plateau. arXiv preprint.
Lee et al. (2024). Grokfast: Accelerated Grokking by Amplifying Slow Gradients. arXiv:2405.20233.